Big Data as a Service
A complete elastic Hadoop cluster with OpenStack + Sahara in 15 minutes
Hi there... I haven't been here for a while for several reasons, that includes a super hyperactive baby girl and a lot of effort building an Enterprise class ready Private cloud based in OpenStack using a tremendous set of new technologies, SDS, SDN, IaaS, PaaS, Containers, Hana and now BigData.
the good thing is, working along with a talented guy as Ramon Morales things are easier to do, brainwork becomes a hobbie on a playground and innovation just flows.
but anyway let's jump on the BigData stuff.

One of our DBA's ask us for a Linux instance on the OpenStack cloud, first questions from me was, purpose ? , so he wanted to try and learn about Hadoop, so I started to look if there was an image ready for it or start to build one from scratch and meet the Hadoop pre-requisites, at the end the DBA won't install the Hadoop platform, that will be the sysadmins or Devops :)
So I was on an interesting situation, reading in deep I found a pararell world about DataProcessing and BigData, and then project Sahara formerly known as Savanna, immediatly I get caught on it.
But WHAT IS SAHARA?
Sahara began life as an Apache 2.0 project and is now an OpenStack integrated project, Sahara enables the fast provisioning and easy management of Hadoop clusters on Openstack, mainstream Hadoop distributions and elastic data processing (EDP) capability similar to Amazon Elastic MapReduce (EMR).
So here are basic steps to add Sahara on an existing OpenStack deployment.
On the OpenStack control Node (ubuntu)
I started searching the packages for Sahara first, didn't break anything on control nodes :)
$ sudo apt-cache search sahara
That gets me sahara, python-saharaclient, and openstack-dashboard, I already have the dashboard installed, so just needed to install sahara package and the python-saharaclient.
$ sudo apt-get install sahara python-saharaclient
Find out the sahara configuratin file, default path is /etc/sahara, there are some samples placed in the sahara directory, you can use the basic sample or generate a new one with
$ sudo tox -e genconfig
That will get you a sahara.conf file, you can modify basic parameters, such as Networking(Neutron), Database(Mysql), Message systems(Rabbit), Identity(Keystone), for a reference guide please see: Sahara Configuration Guide
Then a Database Schema for Shara is needed, you can create it as follows (on an existing empty database)
$ sudo sahara-db-manage --config-file /etc/sahara/sahara.conf upgrade head
my db connection string on sahara.conf file is
connection=mysql://admin:ridiculouspass@localhost:3306/saharadb
Great, we have a database schema for Sahara, please make sure Database hosts is reacheable by sahara node and neutron management network.
Keystone configuration
This is another essencial part for sahara to be accesible in the OpenStack dasboard and for python sahara client to work properly we need to add sahara on keystone catalog
As keystone admin, create the service "sahara" as data_processing type
(keystone_admin)# keystone service-create --name sahara --type data_processing \
--description "Sahara Data Processing"
Next create the endpoint and define the access + Region
(keystone_admin)# keystone endpoint-create --service sahara --region RegionOne \
--publicurl "http://172.16.0.2:8386/v1.1/%(tenant_id)s" \
--adminurl "http://10.0.0.2:8386/v1.1/%(tenant_id)s" \
--internalurl "http://192.168.0.2:8386/v1.1/%(tenant_id)s"
Make sue you match the admin, public and internal network on the new service, you can verify the current endpoints with
(keystone_admin)# keystone endpoint-list
Configure Firewall to Allow Sahara service traffic
Add an INPUT rule allowing TCP traffic on port 8386, and restart iptables
-A INPUT -p tcp -m multiport --dports 8386 -j ACCEPT
Start Sahara service
service sahara-all start
Also you can setup Sahara on a virtual python environment, I didn't try that, but can be found here
Sahara Virtualenv
There are also advanced configurations for Sahara, you can find them here
Sahara Advanced configuration
That is a high level steps for Sahara in OpenStack, so once we have them all and you can see Data Processing panel on Horizon, so from here 15 minutes can start to count to create a cutting-edge fresh hadoop cluster.
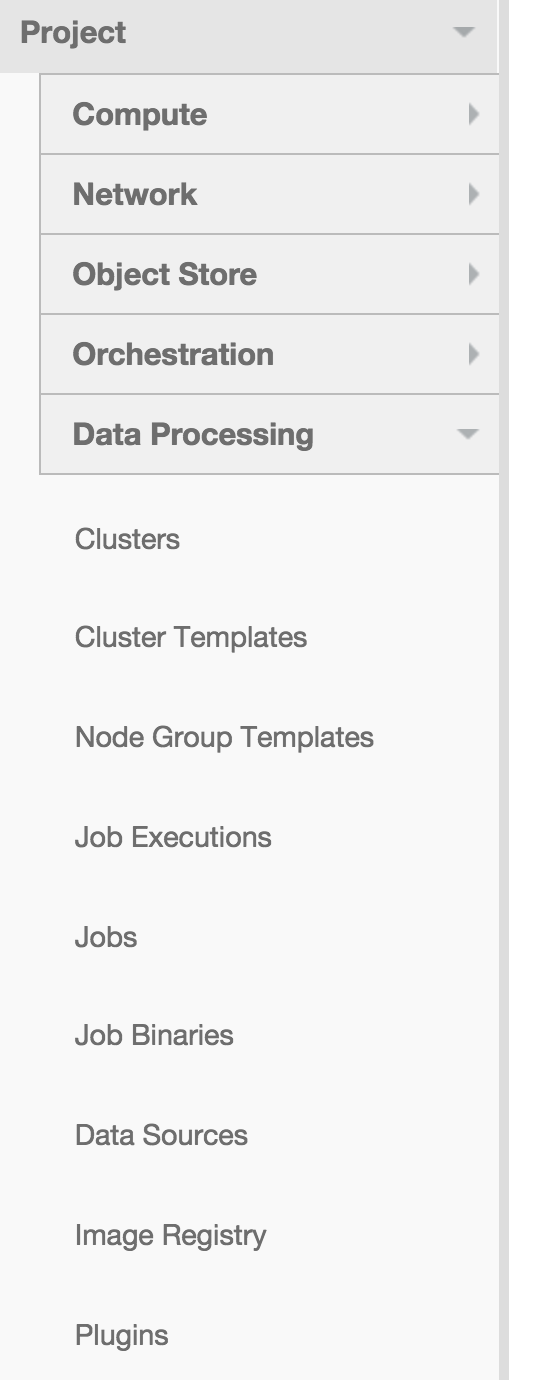
Then there are some pre-configured images for Hadoop vanilla plugin, you can download them from here
Vanilla Plugin
And it can be easily upload to glance, then to the Data processing image registry
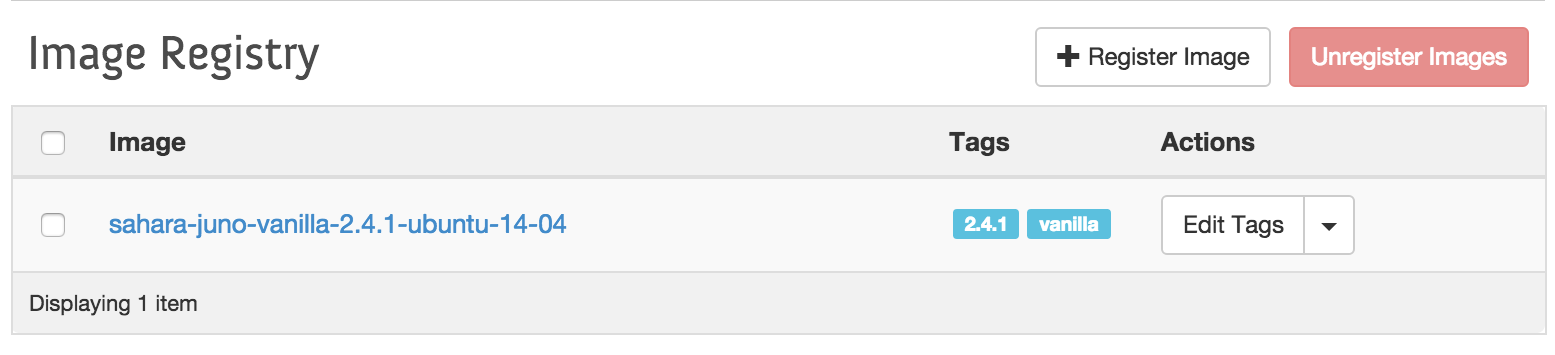
Sahara makes it possible to create nodes and cluster templates, You can mix and match roles for a node, also you can scale out your cluster as many or few nodes you need.
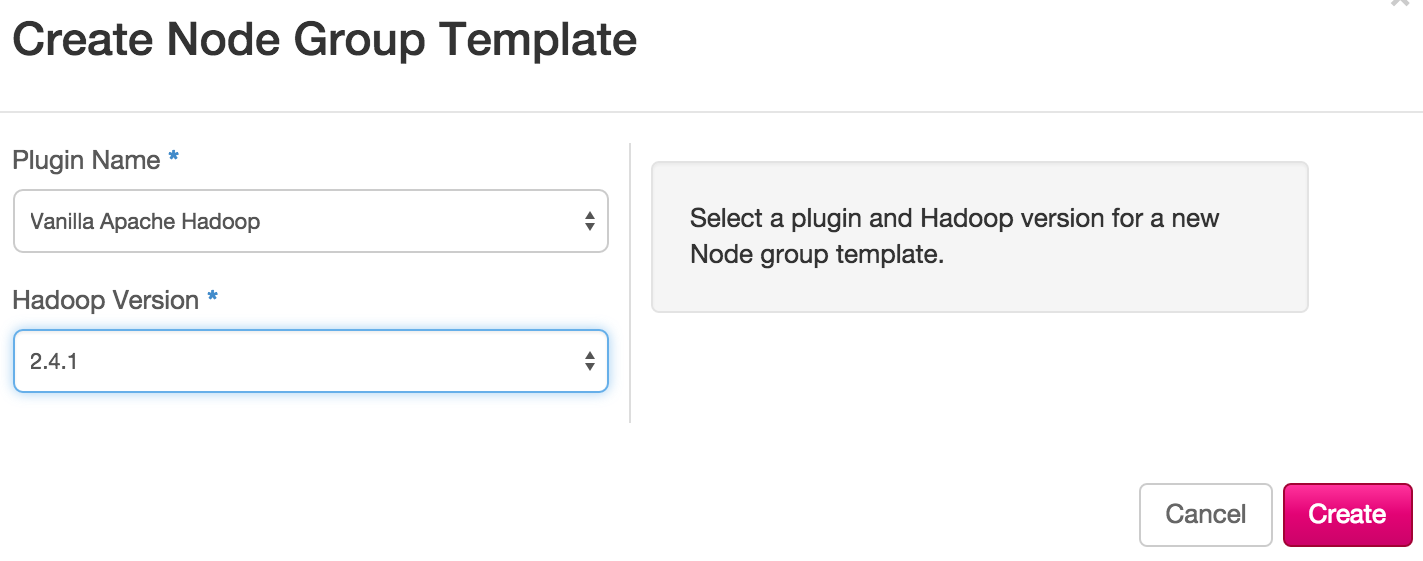
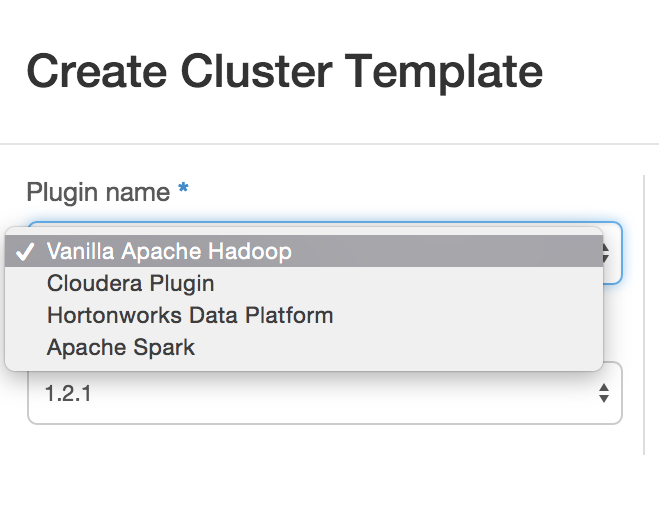
Because I couldn't say it better than mirantis.com
"Manually creating a Hadoop cluster on OpenStack requires spinning up instances, installing Hadoop on each instance, configuring the instances to work together, specifying the namenode, jobtracker, tasktrackers, and any storage nodes, and configuring each of hundreds, or even thousands, of nodes. Why spend all that time on manual configuration — with the possibility of human error — when you can use Sahara to specify node characteristics and roles, click to deploy, and access a individual or multiple robust, stable Hadoop clusters in parallel with minimal delay?"
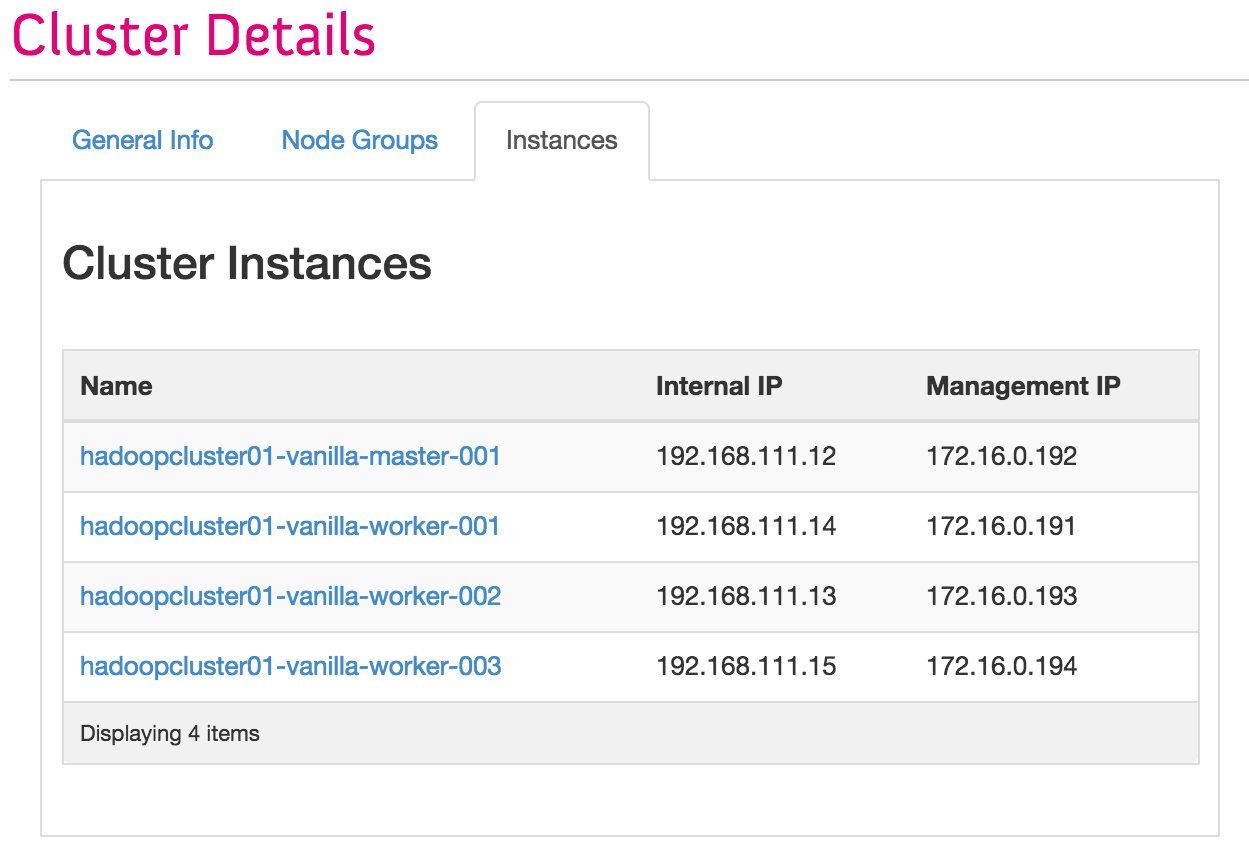
Also the Hadoop cluster can be scalable with no pain, so you can save time
when it comes to create and configure new nodes, only simply add node types by the OpenStack Sahara user interface
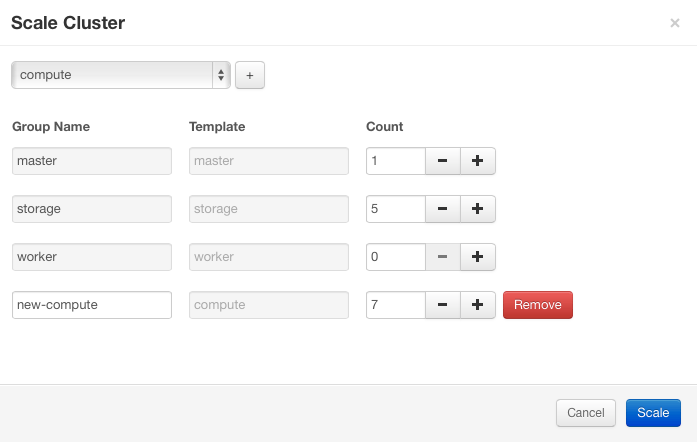
And voila you have a fresh Elastic Hadoop deployment ready in just a few minutes.

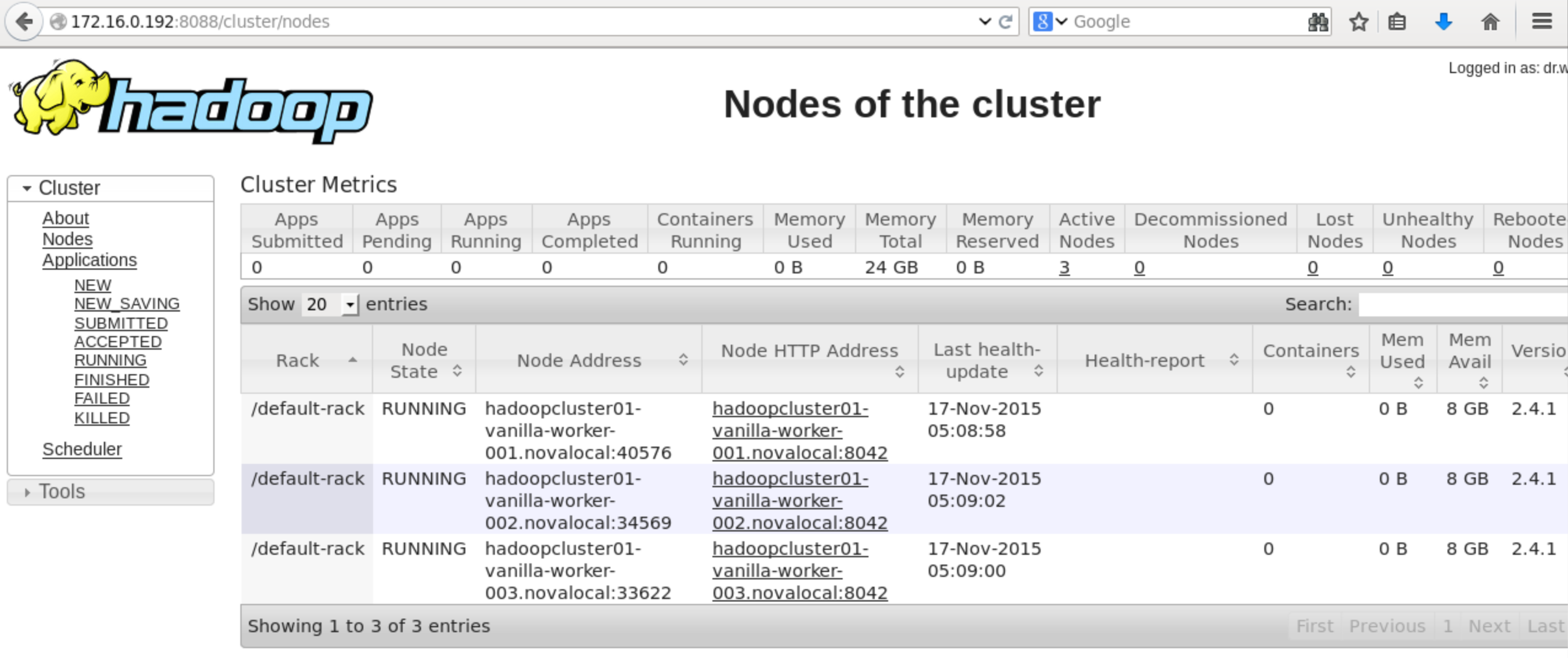
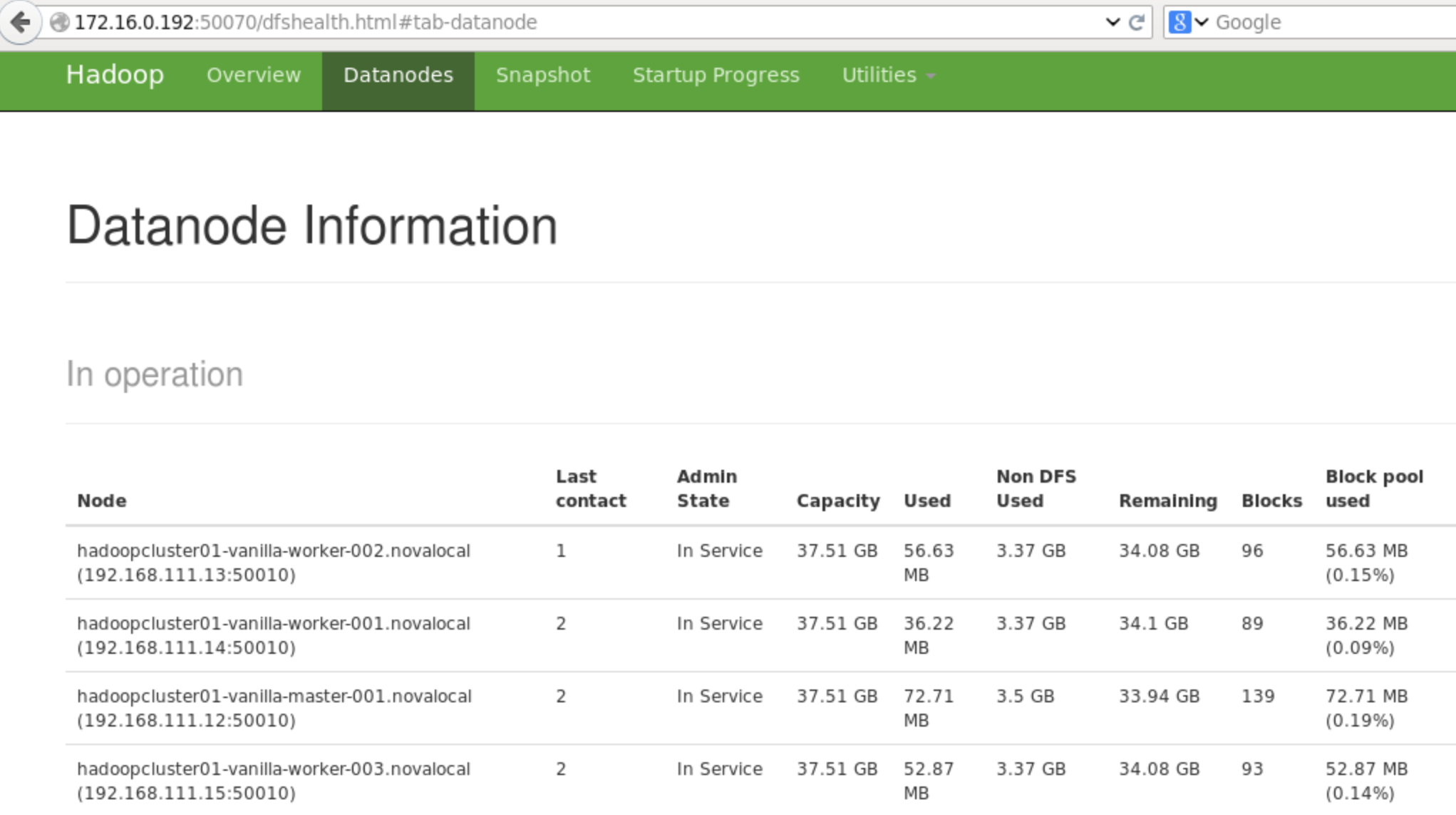
So this is pretty much everything about the installation of Hadoop on OpenStack (Juno)
Next post We'll run a job on the cluster, stay tunned :)
